関数
関数の使い方とヘルプ
Rにおけるデータ分析は、ほとんどが関数(および演算子)を使って進められます。 関数には、関数電卓にあるような対数関数logなどの数学関数だけでなく、回帰分析などのデータ分析を行う関数、作図する関数、外部ファイルの入出力を行う関数など様々なものがあります。既に解説したベクトル、データフレームの作成に用いる c, data.frame も関数です。 さらに、拡張パッケージを導入することにより、世界中で開発された万を超える数の関数が利用可能です。 このページでは、ベクトルやデータフレームに適用できる基本的な関数とパッケージの導入について解説します。
全ての関数は共通して、次のような形で使用します。
関数名(第1引数, 第2引数,…, 引数名a = 引数a, 引数名b = 引数b,…)
上の書き方だけでは分かりませんので、数値を四捨五入する関数roundを例に説明いたします。使い方の分からない関数は、右下のHelpタブで虫メガネの右欄に関数名を入力してEnter(Return)を押すか、Consoleタブで ?関数名 または help(関数名) と入力してEnter(Return)を押すことで、下図のようにHelpタブ上で英語のヘルプを参照することができます。(あるいは、多くの関数はGoogleなどで「r 関数名」などと検索すれば日本語の解説記事も見つかります。)
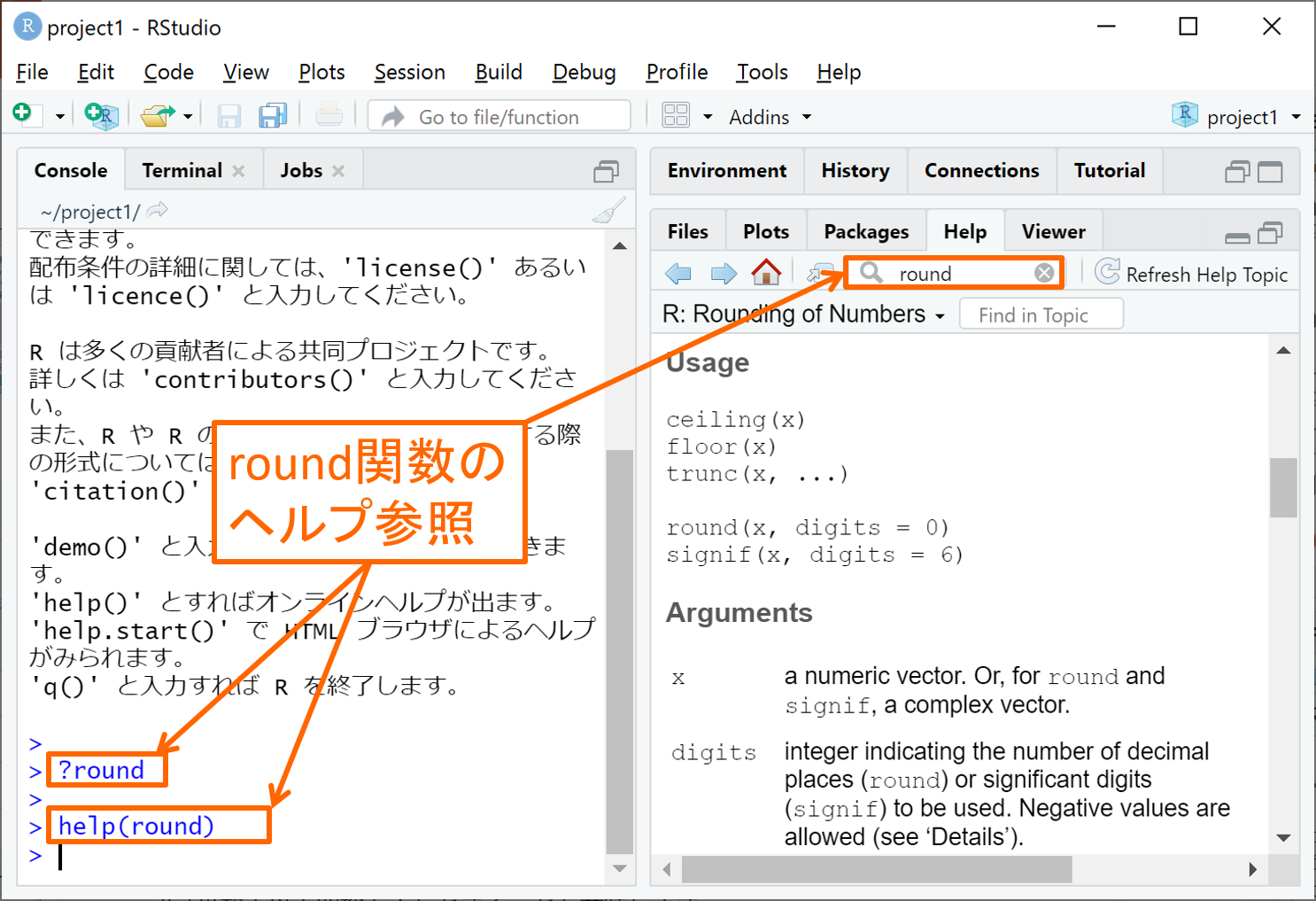
上記のround関数のヘルプでは、round以外の関数もいくつか一緒に解説されていますが、上端から少し下にスクロールしますと下図のUsage節にroundの使い方が次のように書いてあります。
round(x, digits = 0)
この関数の中にある文字が「引数名」です。i番目の引数を第i引数と呼ぶことにしますと、xが第1引数、digitsが第2引数の名前となります。引数の意味はUsage節の下のArguments節に書かれており、xはnumeric vectorすなわち数値ベクトル、digitsは小数点以下何桁より下を四捨五入するか指定する整数となります。上では”digits = 0”と書かれていますが、この”=“より右の値”0”はデフォルト値(省略時規定値)と呼ばれ、round関数の使用時に引数digitsの値をに指定しなかった場合は自動的にdigits = 0(小数点以下四捨五入)とすることを意味します。
それではround関数を実際に使ってみます。以下に示す4つの命令文は全て1.2の小数点以下を四捨五入しています。
round(1.2) # 第1引数 x のみに値を入れる(第2引数 digits はデフォルト値 0 となる)## [1] 1round(1.2, 0) # 第1引数 x と第2引数 digits に順に値を入れる## [1] 1round(x = 1.2, digits = 0) # 第1引数 x と第2引数 digits に引数名を指定して値を入れる## [1] 1round(digits = 0, x = 1.2) # 第2引数 digits と第1引数 x に引数名を指定して値を入れる## [1] 1上の例のように、関数の使い方にはいくつかバリエーションがあることを覚えておいてください。引数の入れ方の注意点をまとめると以下の通りです。
Usageにある順番通りに引数の値を入れる場合には、関数内に引数の値だけ入力すればよい。
Usageにある順番を無視して引数の値を入れる場合には、「引数名 = 引数の値」と引数名を指定する必要がある。
デフォルト値をもつ引数には、値を入れなければ自動的にデフォルト値が入る。
ベクトルに使う関数
ここでは、ベクトル(単一の値の場合も含む)に対して良く使われる関数をごく簡単に紹介します。
まず以下に示すのは、ベクトルの要素ごとに単純な数値演算を行う数学関数です。計算不能な負の値の平方根や対数はNaN(非数値)という結果(以降、戻り値と呼びます)になります。
v = c(-1.24, 0, 4, 0.5) # 数値ベクトルを作成
abs(v) # 絶対値## [1] 1.24 0.00 4.00 0.50floor(v) # 小数点未満切り捨て## [1] -2 0 4 0round(v, 1) # 小数第1位未満を四捨五入## [1] -1.2 0.0 4.0 0.5sqrt(v) # 平方根## [1] NaN 0.0000000 2.0000000 0.7071068log(v, 10) # 対数関数(第2引数は対数の底)## [1] NaN -Inf 0.60206 -0.30103次に以下に示すのは、ベクトルを集計・操作する関数です。それぞれベクトルの集計値あるいは操作されたベクトルを戻り値として返します。
length(v) # ベクトルの要素数## [1] 4sum(v) # 数値ベクトルの総和(全ての要素の和)## [1] 3.26prod(v) # 数値ベクトルの総乗(全ての要素の積)## [1] 0mean(v) # 数値ベクトルの平均(=総和/要素数 sum(v)/length(v))## [1] 0.815sort(v) # ベクトルの要素の並べ替え(デフォルトは昇順)## [1] -1.24 0.00 0.50 4.00sort(v, T) # ベクトルの要素の並べ替え(第2引数にTまたはTRUEを入れると降順になる)## [1] 4.00 0.50 0.00 -1.24上の例で、sort関数の使い方(Usage)は次の通りです。ちなみに、文字列ベクトルもsort関数で並べ替えが可能です。
sort(x, decreasing = FALSE) (第2引数 decreasing がTRUEなら降順、FALSE(デフォルト)なら昇順)
最後に以下に示すのは、ベクトルを値の種類ごとにグルーピングして集計する関数tableとtapplyです。
w = c("A","B","A","C") # 文字列ベクトルを作成
table(w) # ベクトルの値の種類ごとの出現回数を集計## w
## A B C
## 2 1 1tapply(v, w, sum) # w の値の種類ごとの v の値の総和(sum)を集計## A B C
## 2.76 0.00 0.50tapply(v, w, mean) # w の値の種類ごとの v の値の平均(mean)を集計## A B C
## 1.38 0.00 0.50tapply(v, w, sum)/table(w) # w の値の種類ごとの v の値の総和/出現回数=平均 を算出## A B C
## 1.38 0.00 0.50ベクトルの値の種類ごとの出現回数を集計するtable関数は、1行目:集計したベクトル名、2行目:値の種類、3行目:出現回数のように3行にわたって戻り値が表示されます。
tapply関数はやや複雑ですが、第2引数(w)の値の種類ごとの第1引数(v)の値を第3引数の集計関数(sum,meanなど)で集計し、1行目:値の種類、2行目:集計値のように2行にわたって戻り値が表示されます。このように、引数にはベクトルだけでなく関数自体が入ることもあります。
なお、table関数やtapply関数の戻り値は、値の種類を要素名(要素番号の代わり)とした集計値の数値ベクトルとして扱われ、上の最後の例のように数値ベクトルとして四則演算などに用いることができます。
データフレームに使う関数
データフレームはベクトルを列結合したものであるため、以下のように列ごとにベクトルに対する関数が適用できます。
vw = data.frame(v = v, w = w) # ベクトル v と w を列結合したデータフレームを作成
sum(vw$v) # vw$v の総和## [1] 3.26tapply(vw$v, vw$w, mean) # vw$w の値の種類ごとの vw$v の値の平均(mean)を集計## A B C
## 1.38 0.00 0.50ここではさらに、データフレームに対して良く使われる簡単な関数をいくつか紹介しておきます。
nrowとncolは、データフレームの行数と列数を取得する関数。
headとtailは、第1引数のデータフレームの先頭と末尾を第2引数の行数だけ取得する関数。
rownamesとcolnamesは、データフレームの行名(行番号)と列名(変数名)を参照する関数。参照するだけでなく、全部または一部に別の文字列を代入して置き換えることもできます。
以下にその例を示します。
nrow(vw) # データフレームの行数## [1] 4ncol(vw) # データフレームの列数## [1] 2head(vw,2) # データフレームの先頭2行を表示## v w
## 1 -1.24 A
## 2 0.00 Btail(vw,3) # データフレームの末尾3行を表示## v w
## 2 0.0 B
## 3 4.0 A
## 4 0.5 Crownames(vw) # データフレームの行名## [1] "1" "2" "3" "4"colnames(vw)[2] = "ABC" # データフレームの列名(変数名)を一部置き換え
colnames(vw) # データフレームの列名(変数名)## [1] "v" "ABC"パッケージ
Rのパッケージとは、Rの基本機能を拡張するための追加機能の集まりで、関数やデータセットなどが含まれています。Rの基本機能だけではできないことも、パッケージをインストールして利用することで可能になります。
ここでは、後で「回帰と作図」にて紹介するpairs.panels関数を含んでいるpsychパッケージを例に、パッケージをインストールして、パッケージを読み込む方法を解説します。
パッケージには初めからインストール済であるものもあります。下図の右下にあるPackagesタブで、インストール済のパッケージの一覧を見ることができます。一覧の中に目的のパッケージが無かったり、以前に目的のパッケージを使ってから長い年月が経っている(パッケージのバージョンが古い)場合には、次に解説する方法で目的のパッケージをインストールしましょう。
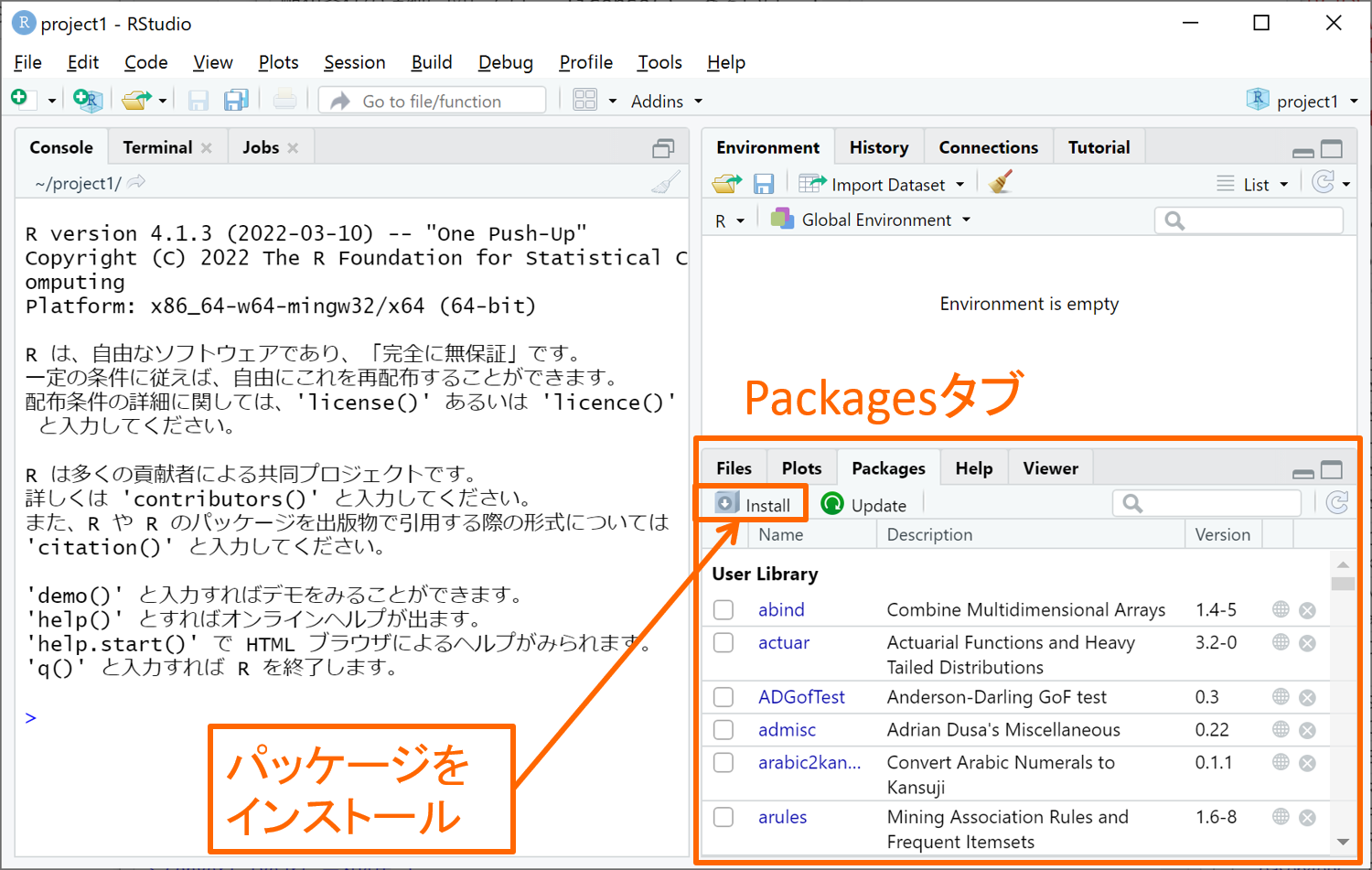
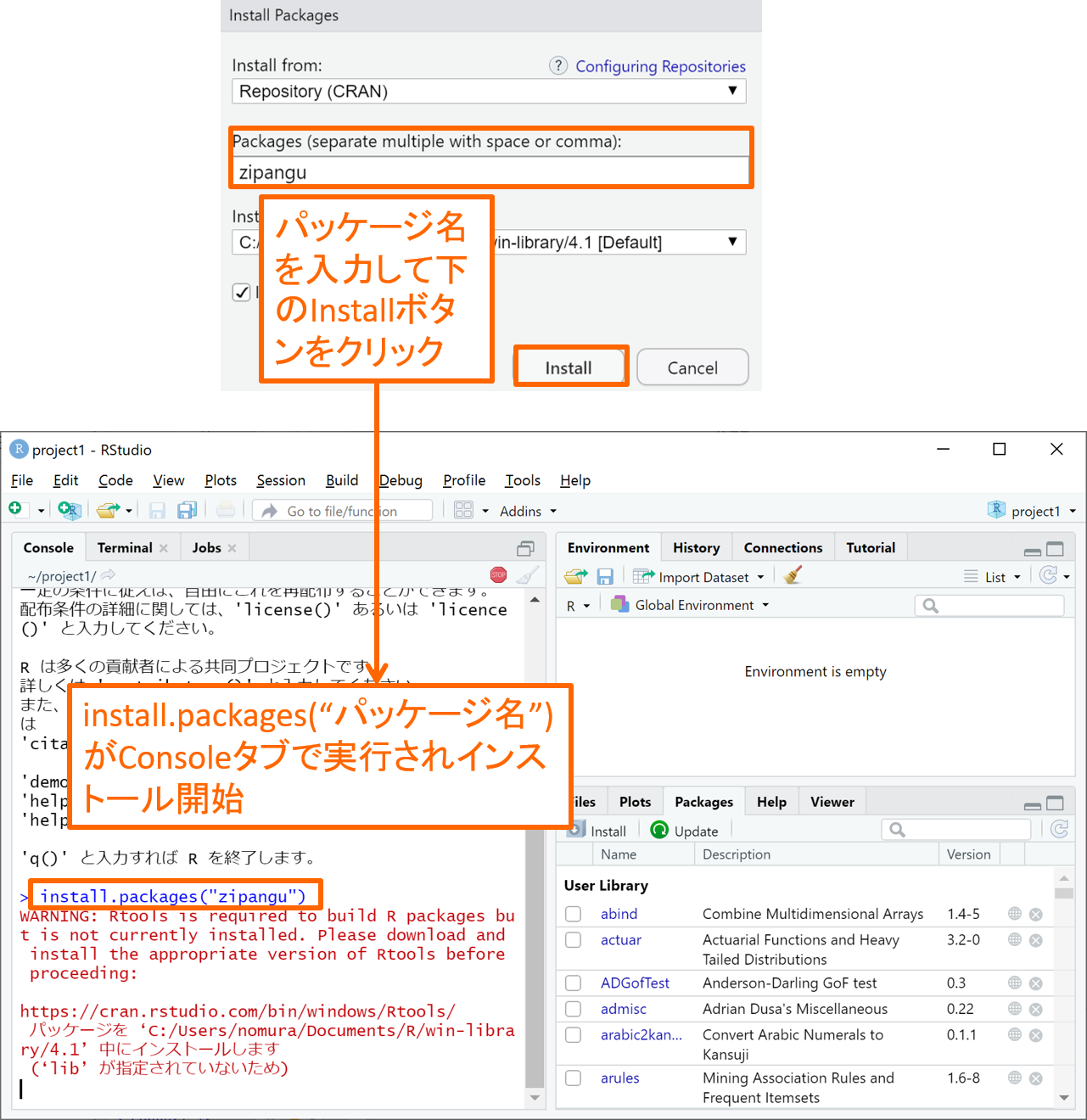
パッケージのインストールは、Consoleタブにinstall.packages(“パッケージ名”)と入力して実行すれば、あとは下図のように自動でインストールが進みます。あるいは、Packagesタブの左上にあるInstallボタンをクリックして出てくる下図のウィンドウの中段にパッケージ名を入力し下のInstallボタンをクリックすると、Consoleタブにinstall.packages(“パッケージ名”)が自動入力されて同じようにインストールが始まります。
インストールが完了すると、下図のようにPackagesタブの一覧にインストールしたパッケージ(psych)が追加されていることが確認できます。ただし、インストールが完了しただけではまだパッケージの関数を使うことはできません。パッケージを利用するには、Consoleタブにlibrary(パッケージ名)と入力して実行するか、Packagesタブの青字のパッケージ名の左にある四角をクリックしてチェックすることで、パッケージを読み込む必要があります。
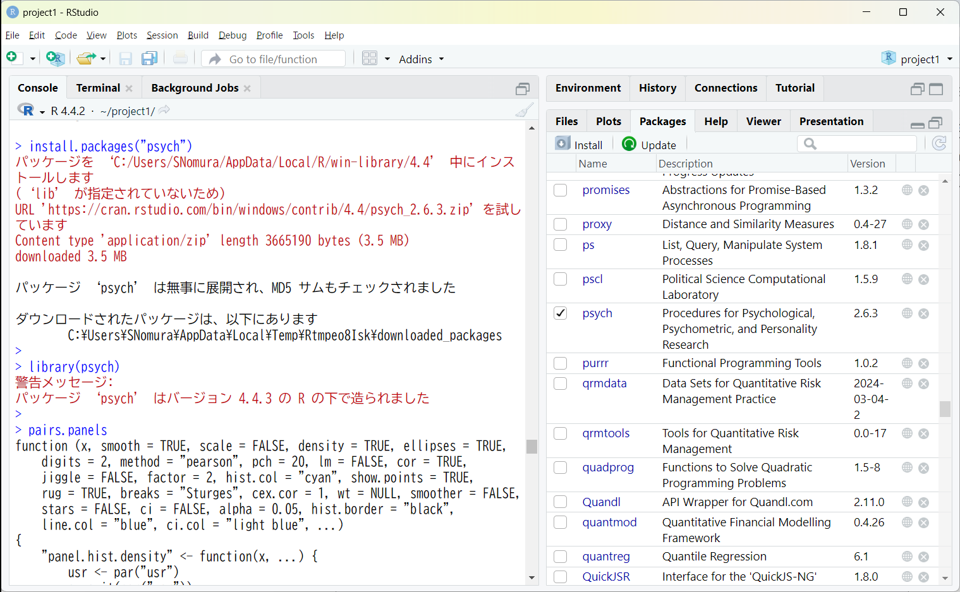
psychパッケージが読み込まれたら、psychパッケージのpairs.panels関数が参照できるようになります。たとえばConsoleタブに関数名だけ入力して実行すると、上図のように関数の引数名やデフォルト値が参照できます。pairs.panels関数の使い方と使用例につきましては「回帰と作図」にて紹介いたします。